Artificial Intelligence
Semantic Calibration in Base Large Language Models vs Instruction Tuning
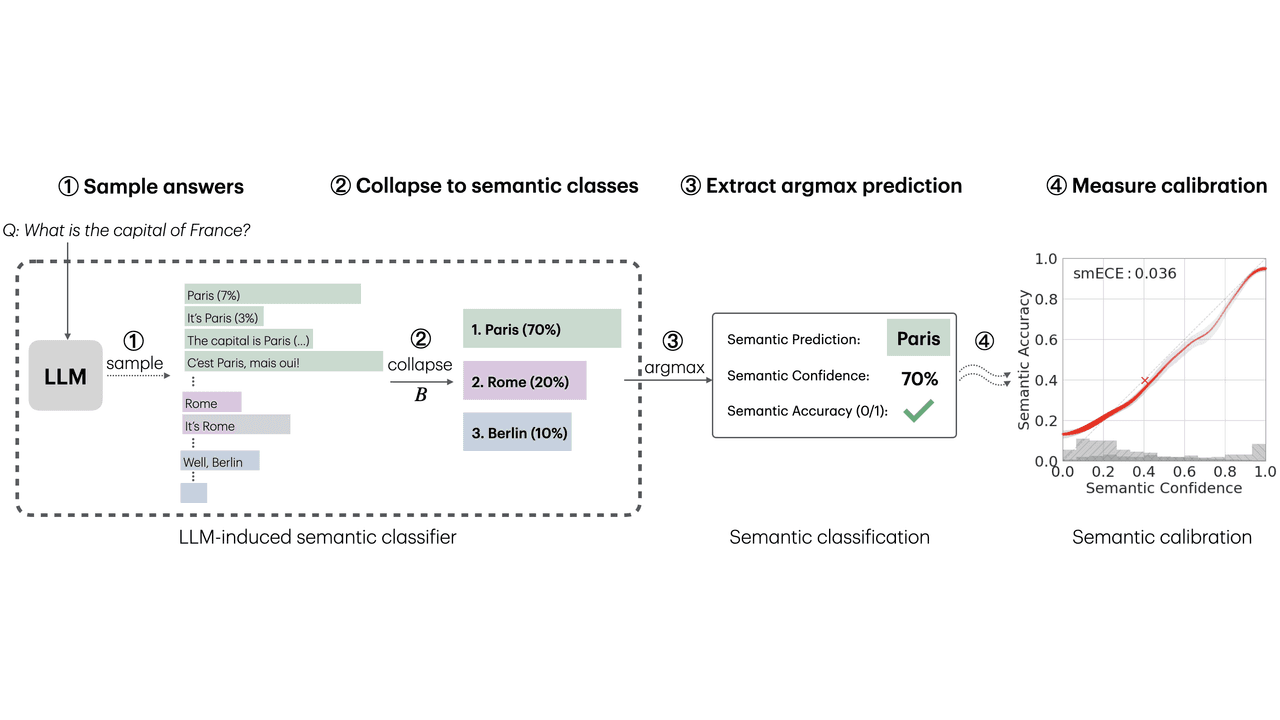
This 2025 study done by researcher at Apple, reveals that base LLMs are remarkably well-calibrated semantically, meaning they know when they are right...
Academic Lite
4 min
Artificial IntelligenceSemantic CalibrationLarge Language Models+2

Artificial Intelligence
LLM-in-Sandbox: How AI Agents Use Virtual Computers to Boost Performance
Researchers created LLM-in-Sandbox, a framework that gives language models access to a virtual computer where they can execute commands, manage files,...
Academic Lite
3 min
Artificial IntelligenceMachine LearningLLM Agents+1