Artificial Intelligence
Academic Lite
Expert Verified
This 2025 study done by researcher at Apple, reveals that base LLMs are remarkably well-calibrated semantically, meaning they know when they are right or wrong, while Reinforcement Learning (RL) instruction-tuning and chain-of-thought reasoning systematically break this ability.
Semantic calibration in base large language models is the ability to accurately estimate confidence in the meaning of their responses. In this 2025 study, researchers found base LLMs are remarkably well-calibrated across 4 datasets, while Reinforcement Learning (RL) instruction-tuning and chain-of-thought reasoning systematically break this ability. This matters because it explains when models "know what they don't know."
Have you ever wondered if an AI actually knows when it is bluffing? This research on semantic calibration in base large language models reveals a fascinating paradox. The raw, pre-trained versions of these models are often better at judging their own accuracy than their polished, instruction-tuned counterparts.
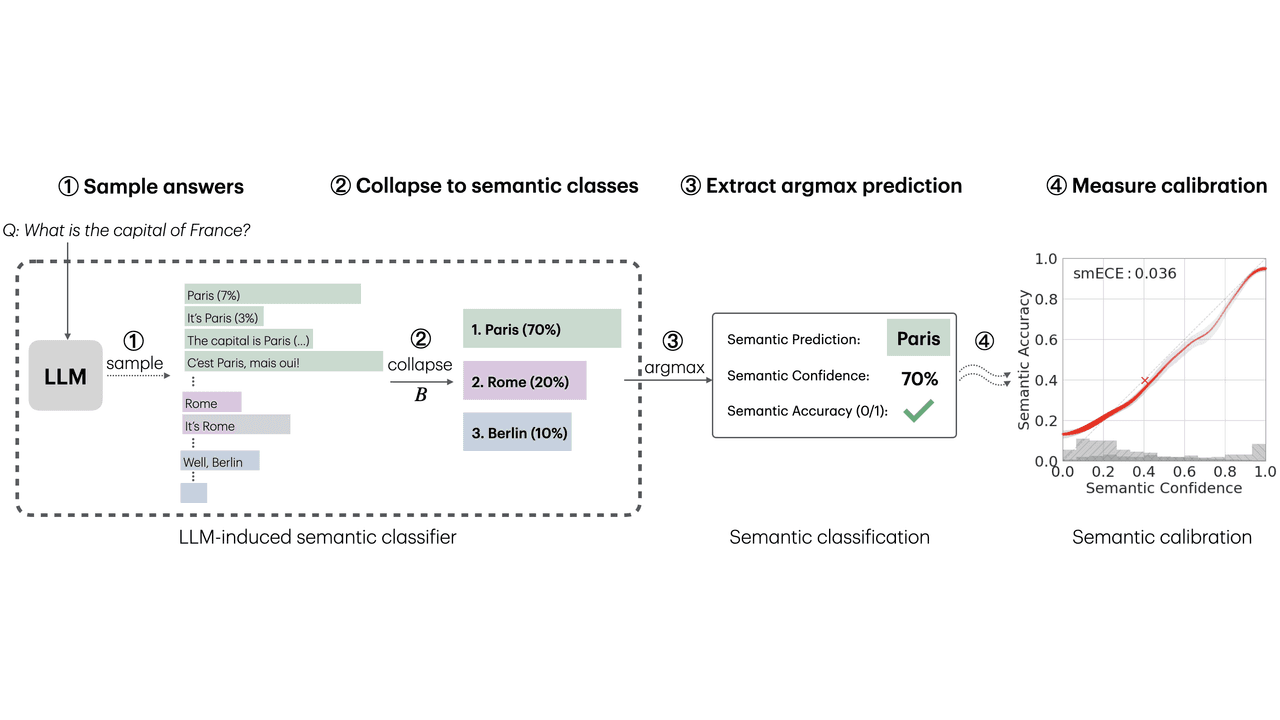
Let me break this down for you. The researchers evaluated models on 4 selected datasets covering world knowledge and mathematical reasoning. They found that base LLMs, which are only pre-trained, are surprisingly good at semantic calibration. This means if a base model says it is 80% confident in an answer, it is actually correct about 80% of the time.
Here is the fascinating part. The study validated three specific predictions. First, base LLMs are semantically calibrated across question-answering tasks. Second, RL instruction-tuning systematically breaks this calibration. Third, chain-of-thought reasoning also breaks calibration. This is similar to studies on uncertainty quantification, but it provides a new theoretical lens. The researchers also looked at model scaling effects. They found no correlation between model capability, measured by semantic accuracy, and calibration error for base models. This differs from prior works that observed improvements in next-token calibration with scale.
So, why does this happen? The paper introduces a theoretical mechanism called "B-calibration." This is a notion of calibration parameterized by a choice of equivalence classes. In this case, the classes are semantic meanings. The theory relies on a recent connection between calibration and local loss optimality.
Essentially, the mechanism treats the LLM as a standard multi-class classifier by collapsing outputs with the same semantic meaning. The theory predicts that semantic calibration emerges when the model can easily predict its own distribution over semantic answer classes before generating a response. Intuitively, the model must "know" how likely it is to generate a "Paris"-type answer before it determines exactly how to phrase that answer.
This builds on earlier research in deep networks. The authors explain that calibration in LLMs differs from other deep networks, like image classifiers, because of training practices. When training LLMs, practitioners monitor test loss closely and stop before it overfits. This keeps the model locally-loss-optimal, which is crucial for calibration. In contrast, image classifiers are often trained until classification error is low, even if test loss increases, leading to miscalibration.
While the findings are compelling, we must acknowledge the limitations. The authors focus on a very specific type of calibration, which is essentially a sampling-based notion. They did not explore verbalized calibration, which is another interesting area. Additionally, the work is primarily scientifically motivated and does not fully explore practical considerations.
One major limitation is computational efficiency. Computing semantic confidence requires sampling an LLM multiple times for the same question, which can be resource-intensive. The study also only evaluated on 4 selected datasets. While they covered diverse domains, it is possible that other datasets, like TruthfulQA, which contains common human misconceptions, might behave differently. The authors note that TruthfulQA fails to satisfy the "in-distribution" requirement of their results, so miscalibration there would be consistent with the theory.
Furthermore, there remain several steps in the conjectured mechanism lacking formal definitions and proofs. Formalizing these in meaningful ways remains an open question. Despite these limitations, this work provides the first principled explanation of when and why semantic calibration emerges in LLMs, offering a valuable tool for understanding model uncertainty.
RLHF breaks calibration because it optimizes the model for specific outputs rather than maintaining local loss optimality. The study found that while base LLMs are well-calibrated, RL instruction-tuning systematically disrupts this ability, causing models to become overconfident or underconfident in their semantic predictions.
B-calibration theory suggests calibration emerges when a model can predict its distribution over semantic answer classes before generating the response. It relies on local loss optimality, meaning the model stops training before overfitting, allowing it to maintain accurate probability estimates over the meaning of its outputs.
The research is limited to a sampling-based notion of calibration and only evaluated on 4 datasets. It also does not address computational efficiency, as measuring semantic confidence requires multiple samples. Additionally, the theoretical mechanism lacks some formal definitions and proofs, leaving gaps for future research.
This article has been reviewed by a PhD-qualified expert to ensure scientific accuracy. While AI assists in making complex research accessible, all content is verified for factual correctness before publication.
The AI Hivemind: Why All Chatbots Sound the Same Now
You’ve noticed it too—AI responses are starting to blend together. Here’s why that’s dangerous.
Prompt Repetition Improves Non-Reasoning LLMs Without Added Latency
Repeating the input prompt improves accuracy across Gemini, GPT, Claude, and Deepseek models in 47 out of 70 benchmarks with zero losses and no added latency.
Anthropic's Assistant Axis: How LLM Persona Drift Causes Harmful AI Behavior
Researchers at Anthropic and Oxford identified a linear 'Assistant Axis' in LLM activation space that governs persona stability. Activation capping along this axis reduced harmful responses by nearly 60% without degrading model capabilities.
No comments yet. Be the first to share your thoughts!
Get notified when we publish new articles. No spam, unsubscribe anytime.