Artificial Intelligence
Academic Lite
Expert Verified
TurboQuant online vector quantization distortion rate optimization achieves near-optimal results within a 2.7 factor of theoretical bounds. It ensures absolute quality neutrality in KV cache quantization at 3.5 bits per channel.
TurboQuant is a data-oblivious algorithm for online vector quantization that minimizes distortion. It achieves near-optimal distortion rates within a small constant factor of theoretical limits. This matters because it maintains absolute quality neutrality in KV cache quantization at 3.5 bits per channel while reducing indexing time to virtually zero.
Have you ever wondered how we can efficiently compress massive amounts of data without losing the essential geometric structure needed for AI models? TurboQuant online vector quantization distortion rate optimization offers a fascinating solution to this problem by tackling both mean-squared error and inner product distortion head-on. Let me break this down for you.
The evidence suggests that TurboQuant performs exceptionally well when stacked against the mathematical limits of what is possible. The researchers provided a formal proof of information-theoretic lower bounds, demonstrating that TurboQuant closely matches these best achievable distortion rates. Specifically, it differs from the theoretical optimum by only a small constant factor of approximately 2.7. This is a significant achievement because existing methods often fail to achieve optimal distortion rates across all bit-widths and dimensions.
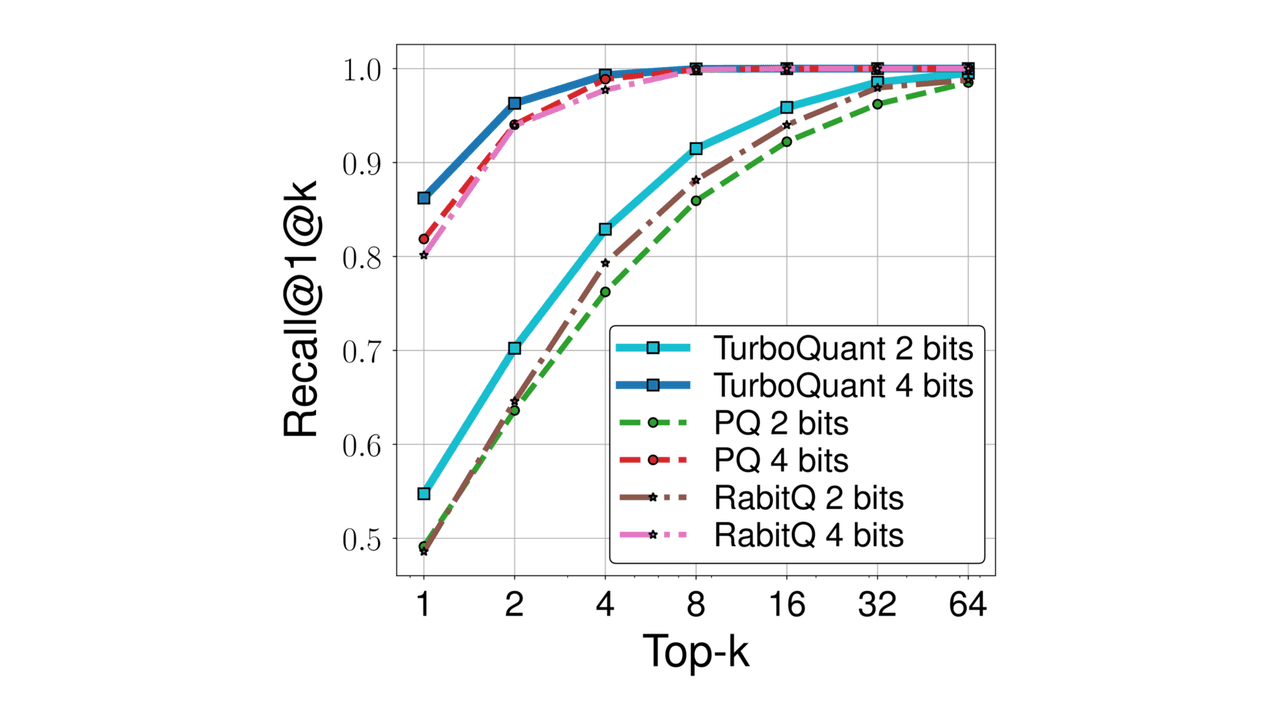
In practical experiments, the results were even more striking. For KV cache quantization, the method achieved absolute quality neutrality with just 3.5 bits per channel. Even when pushed to 2.5 bits per channel, there was only marginal quality degradation. Furthermore, in nearest neighbor search tasks, TurboQuant outperformed existing product quantization techniques in terms of recall. Perhaps most impressively, it reduced indexing time to virtually zero, making it highly efficient for real-time applications.
Here is the fascinating part about the engineering behind this. The algorithm works by randomly rotating input vectors, which induces a concentrated Beta distribution on the coordinates. It leverages the near-independence property of distinct coordinates in high dimensions to simply apply optimal scalar quantizers to each coordinate. This data-oblivious approach makes it particularly suitable for online applications where data might not be known in advance.
However, the researchers recognized a subtle issue. MSE-optimal quantizers introduce bias in inner product estimation. To solve this, they proposed a clever two-stage approach. First, they apply an MSE quantizer, followed by a 1-bit Quantized JL (QJL) transform on the residual. This results in an unbiased inner product quantizer, effectively addressing the shortcomings of standard methods. This builds on earlier research in Shannon's source coding theory but adapts it for modern high-dimensional vector problems.
The primary applications for this technology lie in areas requiring efficient data compression and fast retrieval, such as large language model KV caches and nearest neighbor search databases. By achieving quality neutrality at lower bit rates, TurboQuant allows for significant memory savings without sacrificing model performance.
Regarding limitations, the study acknowledges that while the method achieves near-optimal rates, it is still bounded by a constant factor gap of about 2.7 from the absolute theoretical lower bound. Additionally, while the method is data-oblivious and efficient, the paper focuses on theoretical validation and specific experimental setups like KV cache and nearest neighbor tasks. Further research might be needed to see how it generalizes to other domains or more complex data distributions. Nonetheless, the capability to reduce indexing time to zero while maintaining high recall represents a major step forward for vector quantization technology.
TurboQuant is a data-oblivious algorithm designed for online vector quantization that minimizes distortion in high-dimensional Euclidean vectors. It achieves near-optimal distortion rates within a small constant factor of approximately 2.7 from theoretical lower bounds. The method works by randomly rotating input vectors and applying optimal scalar quantizers to each coordinate.
The researchers use a two-stage approach because MSE-optimal quantizers introduce bias in inner product estimation. By applying an MSE quantizer first and then a 1-bit Quantized JL transform on the residual, TurboQuant creates an unbiased inner product quantizer. This mechanism allows it to address both mean-squared error and inner product distortion effectively.
Experimental results showed that TurboQuant achieved absolute quality neutrality in KV cache quantization with 3.5 bits per channel and marginal degradation at 2.5 bits per channel. In nearest neighbor search tasks, it outperformed existing product quantization techniques in recall while reducing indexing time to virtually zero.
This article has been reviewed by a PhD-qualified expert to ensure scientific accuracy. While AI assists in making complex research accessible, all content is verified for factual correctness before publication.
The AI Hivemind: Why All Chatbots Sound the Same Now
You’ve noticed it too—AI responses are starting to blend together. Here’s why that’s dangerous.
Prompt Repetition Improves Non-Reasoning LLMs Without Added Latency
Repeating the input prompt improves accuracy across Gemini, GPT, Claude, and Deepseek models in 47 out of 70 benchmarks with zero losses and no added latency.
Anthropic's Assistant Axis: How LLM Persona Drift Causes Harmful AI Behavior
Researchers at Anthropic and Oxford identified a linear 'Assistant Axis' in LLM activation space that governs persona stability. Activation capping along this axis reduced harmful responses by nearly 60% without degrading model capabilities.
No comments yet. Be the first to share your thoughts!
Get notified when we publish new articles. No spam, unsubscribe anytime.