Artificial Intelligence
Academic Lite
Expert Verified
Repeating the input prompt improves accuracy across Gemini, GPT, Claude, and Deepseek models in 47 out of 70 benchmarks with zero losses and no added latency.
Prompt repetition for non-reasoning LLMs is a deceptively simple technique that boosts accuracy across major AI models. In a 2025 Google study, researchers found that simply repeating the user's prompt, transforming <QUERY> into <QUERY><QUERY> (instead of one request/query, having double requests repeating) which improved performance in 47 out of 70 benchmark-model combinations with zero losses, all without increasing output length or latency. This matters because it offers a free, drop-in upgrade for any system using large language models without reasoning enabled.
Here's what makes this so compelling: we spend enormous effort on prompt engineering, fine-tuning, and architectural innovations, yet a research team at Google just demonstrated that copying and pasting the prompt can meaningfully improve model accuracy. Let me break this down for you.
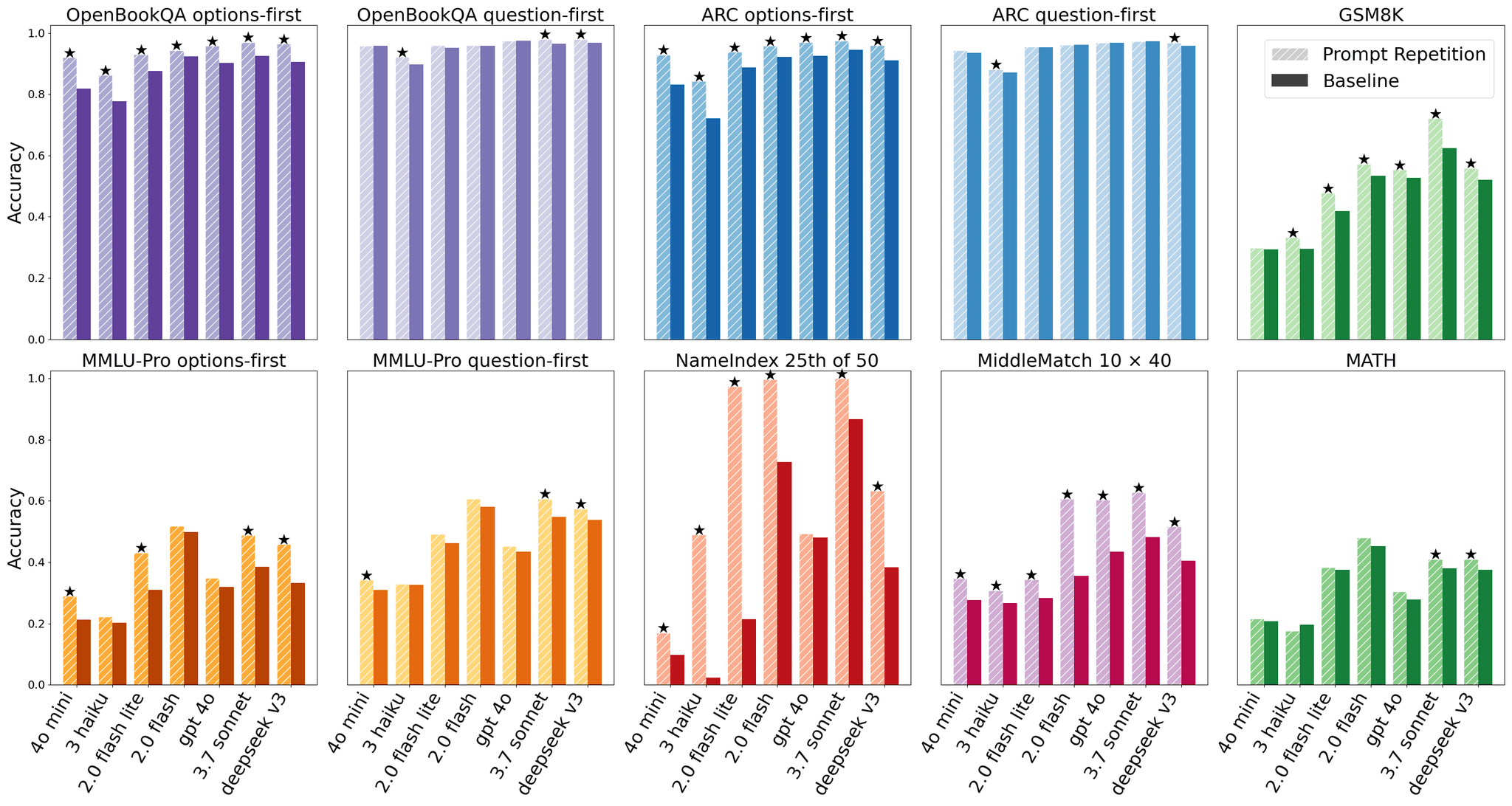
The core finding is striking in its consistency. The researchers tested 7 popular models — Gemini 2.0 Flash, Gemini 2.0 Flash Lite, GPT-4o-mini, GPT-4o, Claude 3 Haiku, Claude 3.7 Sonnet, and Deepseek V3 — across 7 benchmarks including ARC Challenge, OpenBookQA, GSM8K, MMLU-Pro, MATH, and two custom tasks (NameIndex and MiddleMatch).
Using the McNemar statistical test with a p-value threshold below 0.1, prompt repetition achieved 47 wins out of 70 benchmark-model combinations with exactly 0 losses. Every single model tested showed improvement. The gains were especially dramatic on custom tasks: prompt repetition boosted Gemini 2.0 Flash-Lite's accuracy on NameIndex from a mere 21.33% to 97.33%, that's not a typo.
For multiple-choice benchmarks, the researchers tested two orderings: question-first (where the question precedes the answer options) and options-first (where answer choices appear before the question). As expected, the options-first configuration showed larger improvements with prompt repetition, since without it the model must process answer options before ever seeing the question, which is a fundamental limitation of causal attention..
When reasoning was enabled (step-by-step thinking), the results were neutral to slightly positive: 5 wins, 1 loss, and 22 neutral outcomes. This makes sense, and I'll explain why in a moment.
This is where the elegance lies. LLMs are typically trained as causal language models, meaning each token can only attend to tokens that came before it (never future tokens). So if your prompt is structured as <CONTEXT> <QUESTION>, the context tokens never get to "see" the question. The question tokens attend to the context, but not vice versa.
By repeating the prompt, you transform the input into <CONTEXT> <QUESTION> <CONTEXT> <QUESTION>. Now, in the second repetition, every token from the context can attend to the question tokens from the first copy. Essentially, every prompt token gets to attend to every other prompt token which then something that's normally impossible in a left-to-right causal architecture.
Here's the fascinating part: reasoning models trained with reinforcement learning often spontaneously learn to repeat parts of the user's request in their chain-of-thought. Prompt repetition achieves a similar effect but moves it to the prefill stage, which is parallelizable and doesn't add generated tokens. The output format stays identical, making this a true drop-in replacement.
To confirm the gains aren't simply from longer inputs, the researchers tested a padding method that added periods to match the repeated prompt's length. As expected, padding did nothing and the improvement genuinely comes from the semantic repetition, not input length.
They also explored variants: a verbose repetition and triple repetition (×3). Triple repetition sometimes substantially outperformed double repetition on tasks like NameIndex and MiddleMatch, suggesting further research into optimal repetition strategies could yield even bigger gains.
The practical implications are immediate. Since prompt repetition doesn't change output length, format, or latency for most models, it can be deployed as a simple default setting in existing LLM systems without reasoning. The researchers measured both average and median output lengths plus empirical latency across all models and found no increase — with one exception: Anthropic's Claude models showed increased latency for very long requests, likely because the prefill stage itself takes longer with doubled input.
That caveat points to a real limitation: doubling the prompt doubles the prefill computation. For short prompts this is negligible, but for very long contexts, the cost could become meaningful. The paper also tested only API-based inference in February and March 2025, so results may vary with different model versions or deployment configurations.
The researchers outline 13 future directions, including fine-tuning models on repeated prompts, repeating only parts of longer prompts, applying the technique to non-text modalities like images, and exploring interactions with techniques like selective attention. Building on earlier work in causal attention mechanisms and similar to studies on prompt engineering optimization, this research opens a surprisingly rich vein of investigation.
The bottom line? Sometimes the simplest ideas are the most powerful. If you're running LLM inference without reasoning, prompt repetition is essentially a free accuracy boost waiting to be deployed.
Prompt repetition is a technique where you simply copy and paste the user's query, transforming a single prompt into a doubled prompt. In a 2025 Google study testing 7 major AI models across 7 benchmarks, this method improved performance in 47 out of 70 test combinations with zero losses, all without increasing output length or response time. In some cases, like with Gemini 2.0 Flash-Lite on the NameIndex task, accuracy jumped dramatically from 21.33% to 97.33%.
Large language models are trained as causal language models, meaning each word can only pay attention to words that came before it, never future words. When you repeat the prompt, the context from the first copy becomes visible to the question in the second copy, allowing every part of the prompt to attend to every other part. This overcomes a fundamental limitation of the left-to-right processing architecture and helps the model better understand the relationship between context and question.
The main limitation is that doubling the prompt doubles the prefill computation, which is negligible for short prompts but could become costly for very long contexts. Anthropic's Claude models showed increased latency for very long requests when using prompt repetition. Additionally, the technique works best for models without reasoning capabilities enabled, as reasoning models already learn to repeat parts of prompts internally during their step-by-step thinking process.
This article has been reviewed by a PhD-qualified expert to ensure scientific accuracy. While AI assists in making complex research accessible, all content is verified for factual correctness before publication.
The AI Hivemind: Why All Chatbots Sound the Same Now
You’ve noticed it too—AI responses are starting to blend together. Here’s why that’s dangerous.
Anthropic's Assistant Axis: How LLM Persona Drift Causes Harmful AI Behavior
Researchers at Anthropic and Oxford identified a linear 'Assistant Axis' in LLM activation space that governs persona stability. Activation capping along this axis reduced harmful responses by nearly 60% without degrading model capabilities.
AI in Medicine Just Got a Whole Lot Smarter
Generalist medical AI is coming—think of it as a jack-of-all-trades doctor in your computer.
Süleyman
Feb 24, 2026
Hi clumsy, I think what they have found that, just repeating what you would like to write to AI/LLM just repeated two times makes it better for AI to provide better result for you that increase the accuracy basically.
clumsy_scientist
Feb 24, 2026
ok thats very ınteresting. So what if rather than <contex><queston><contex><questıon>, just wrıte <contex><queston> and tell AI to read the text agaın and thınk, would that also work?????
Get notified when we publish new articles. No spam, unsubscribe anytime.