Artificial Intelligence
Academic Lite
Expert Verified
Meta-Harness automated LLM harness optimization code improves text classification by 7.7 points and math reasoning by 4.7 points using filesystem access to prior execution traces.
Meta-Harness is an outer-loop system that automatically searches over harness code for LLM applications. In this study, Meta-Harness improved online text classification by 7.7 points while using 4x fewer context tokens. This matters because it automates harness engineering to outperform manual methods by leveraging rich diagnostic data.
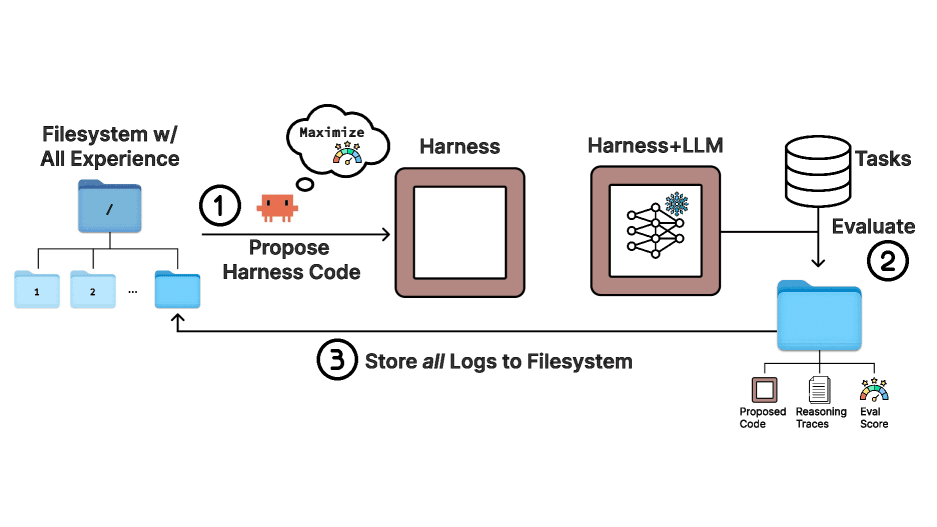
Changing the code harness around a fixed large language model can create a 6x performance gap, yet this process remains largely manual. Let me break down how Meta-Harness automated LLM harness optimization code uses a filesystem to search over harnesses and achieve state-of-the-art results without relying on compressed feedback.
The results from this 2026 Stanford and MIT research are quite striking. On online text classification, harnesses discovered by Meta-Harness improved over Agentic Context Engineering (ACE) by 7.7 points while using 4x fewer context tokens. It matched the next-best text optimizer's final performance after 60 proposals with only four. In retrieval-augmented math reasoning, a single discovered harness improved accuracy on 200 IMO-level problems by 4.7 points on average across five held-out models. On TerminalBench-2, the discovered harness surpassed the hand-engineered Terminus-KIRA and ranked number one among all Haiku 4.5 agents.
Here is the fascinating part. Unlike existing text optimizers that compress feedback too aggressively, Meta-Harness uses an agentic proposer that accesses the source code, scores, and execution traces of all prior candidates through a filesystem. This allows the system to reason over raw prior code rather than relying on lossy summaries. In the most demanding setting, the proposer reads a median of 82 files per iteration, referencing over 20 prior candidates per step. A single evaluation can produce up to 10,000,000 tokens of diagnostic information, which is roughly three orders of magnitude beyond the largest feedback budgets used in prior text optimization settings. This builds on earlier research in credit assignment and meta-learning, applying it to the specific domain of harness engineering.
Beyond outperforming existing harnesses, the discovered strategies generalize to out-of-distribution classification datasets and unseen base models in the math setting. The search run completes in a few hours of wall-clock time and produces readable, transferable strategies. However, the authors acknowledge that overfitting in code space is a concern, though it is more inspectable than weight-space overfitting. The experiments demonstrate that harness search works with one particularly strong coding-agent proposer, Claude Code, but a broader study of how the effect varies across proposer agents remains for future work. A natural next step is co-evolving the harness and the model weights.
Meta-Harness improves text classification by discovering harnesses that outperform Agentic Context Engineering (ACE) by 7.7 points. It achieves this while using 4x fewer context tokens, matching the final performance of other optimizers after only four proposals instead of 60.
Meta-Harness uses filesystem access to allow the proposer to selectively inspect raw prior code, scores, and execution traces rather than relying on compressed summaries. This enables the system to process up to 10,000,000 tokens of diagnostic information per evaluation, significantly exceeding the 100 to 30,000 token limits of prior methods.
While Meta-Harness ranked number one among Haiku 4.5 agents and second among Opus 4.6 agents, the study noted it was unable to reproduce the higher scores of the top-ranking ForgeCode agent from publicly available code. Additionally, the research is limited to using Claude Code as the proposer agent, leaving broader agent variations for future study.
This article has been reviewed by a PhD-qualified expert to ensure scientific accuracy. While AI assists in making complex research accessible, all content is verified for factual correctness before publication.
The AI Hivemind: Why All Chatbots Sound the Same Now
You’ve noticed it too—AI responses are starting to blend together. Here’s why that’s dangerous.
Prompt Repetition Improves Non-Reasoning LLMs Without Added Latency
Repeating the input prompt improves accuracy across Gemini, GPT, Claude, and Deepseek models in 47 out of 70 benchmarks with zero losses and no added latency.
Anthropic's Assistant Axis: How LLM Persona Drift Causes Harmful AI Behavior
Researchers at Anthropic and Oxford identified a linear 'Assistant Axis' in LLM activation space that governs persona stability. Activation capping along this axis reduced harmful responses by nearly 60% without degrading model capabilities.
No comments yet. Be the first to share your thoughts!
Get notified when we publish new articles. No spam, unsubscribe anytime.